LLMEval-Fair: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Published in ACL 2026 Submission (Under Review), 2025
LLMEval-Fair studies a core reliability issue in LLM benchmarking: whether leaderboard gains reflect real capability growth, or partial overfitting to static public tests.
Current status: Submitted to ACL 2026 (under review).
Public version: arXiv preprint available.
Note: DBLP currently indexes the preprint entry under the title LLMEval-3 (
abs-2508-05452).
![]()
Benchmark scope
From the project repository:
- 13 major disciplines (philosophy to medicine and engineering)
- 50+ sub-disciplines
- ~200,000 generative QA items in the current bank
- design target is continued expansion toward larger-scale coverage
Unlike multiple-choice-only setups, this benchmark emphasizes generative answering (short answer, analysis, calculation, essay-style tasks).
Core evaluation design
Dynamic sampling + anti-cheating protocol
- Each run samples a fresh subset (reported 1,000 questions per evaluation run)
- For same-institution model submissions, repeated exposure is controlled
- Questions are delivered sequentially online to reduce crawling/harvesting risk
Judge-based scoring
- Automated scoring with rubric-aligned prompts
- Per-question score mapped from a discrete scale
- Focus on both answer correctness and reasoning validity
Two-score reporting
- Absolute score: raw normalized performance
- Relative score: normalized to current SOTA baseline
This two-view setup reduces interpretation bias caused by changing model ceilings over time.
Longitudinal finding
The public leaderboard and temporal tracking emphasize that model progress is non-uniform across disciplines, and simple one-time benchmark snapshots can be misleading without contamination controls and timeline context.
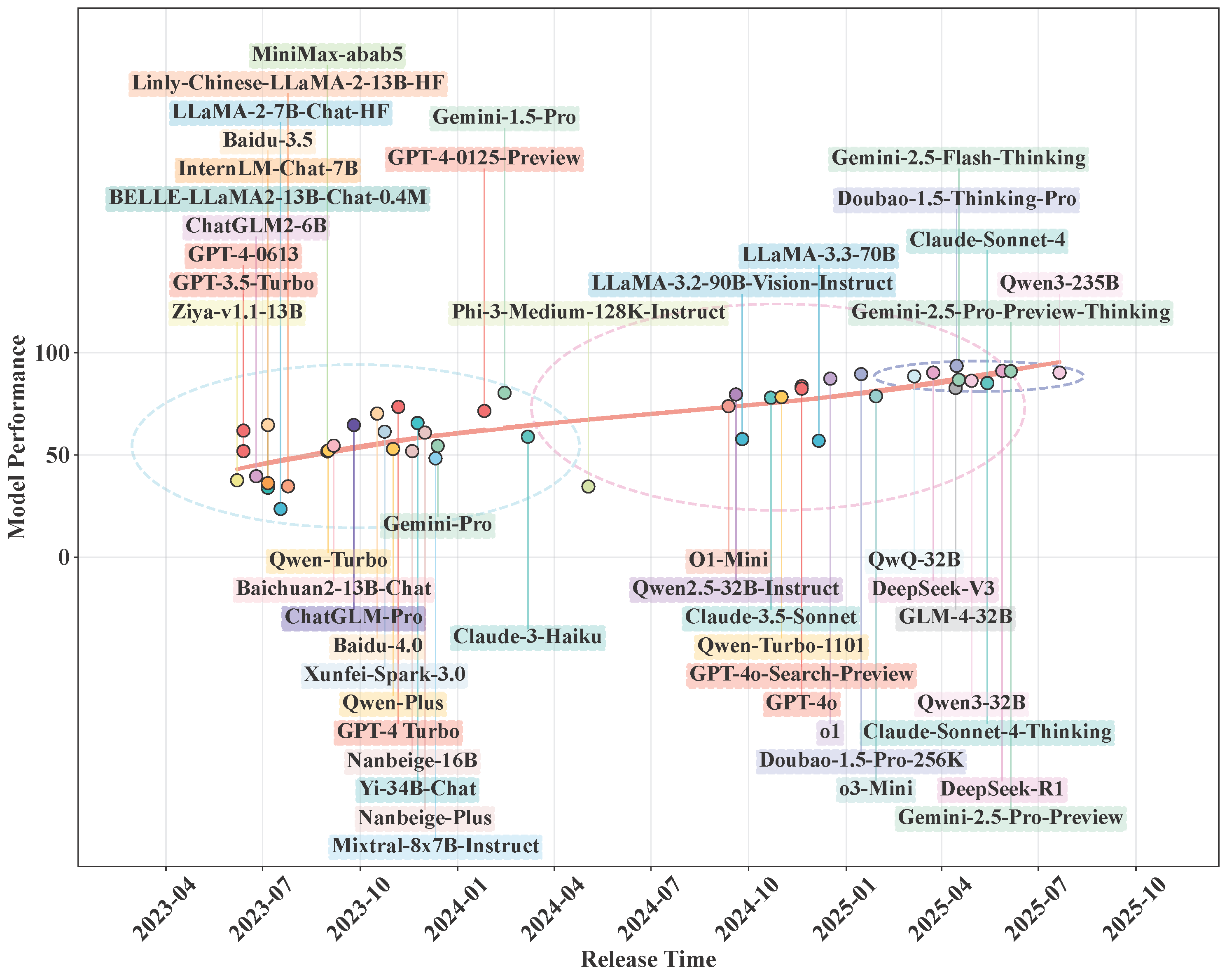
Repository usage notes
The repository is positioned as a benchmark + leaderboard project. For serious comparison, the key principle is to keep:
- fixed scoring protocol
- fresh question sampling
- strict submission/evaluation process control
Project link: github.com/HuayuSha/LLMEval-3
Leaderboard website: llmeval.com
Practical takeaway
If your goal is robust model comparison over time, LLMEval-Fair’s main value is not only the dataset size, but the evaluation governance design: dynamic tests, anti-leakage constraints, and temporal analysis as first-class components.
Citation
@article{abs-2508-05452,
author = {Ming Zhang and
Yujiong Shen and
Jingyi Deng and
Yuhui Wang and
Yue Zhang and
Junzhe Wang and
Shichun Liu and
Shihan Dou and
Huayu Sha and
Qiyuan Peng and
Changhao Jiang and
Jingqi Tong and
Yilong Wu and
Zhihao Zhang and
Mingqi Wu and
Zhiheng Xi and
Mingxu Chai and
Tao Liang and
Zhihui Fei and
Zhen Wang and
Mingyang Wan and
Guojun Ma and
Tao Gui and
Qi Zhang and
Xuanjing Huang},
title = {LLMEval-3: {A} Large-Scale Longitudinal Study on Robust and Fair Evaluation
of Large Language Models},
journal = {CoRR},
volume = {abs/2508.05452},
year = {2025},
url = {https://doi.org/10.48550/arXiv.2508.05452},
doi = {10.48550/ARXIV.2508.05452},
eprinttype = {arXiv},
eprint = {2508.05452},
biburl = {https://dblp.org/rec/journals/corr/abs-2508-05452.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}